
I’ve been working on a project recently, and it may come across as counter-intuitive, but it has involved creating a Puppet environment in AWS. This is a bit different to the way I would normally work with an AWS deployment, but the future of the project will end up being onsite as well as cloud, and involves Windows as well as Linux. The customer manages these as long life servers rather than a distinct dynamic environment.
In either case this was a large greenfield project with the endgame being a continuous delivery system for a middleware stack. If I was to do a blog on the entire thing, it would probably take 4 months to complete (Though this blog entry has taken that long anyway). So I have pulled out a short interesting part.
An existing Puppet Environment
I’m not going to go into the setup of a Puppet server, that’s for another time, so we are going to base the examples on the fact an existing Puppet Enterprise server exists and DNS works, and we do have a Puppet control-repo correctly configured. This can work with the Puppet Open Source server as well.
Now what we wanted to achieve here is the creation of AWS instances that will automatically register with the Puppet Master and run their configuration with, as you should expect, zero input from admins. The old process would have involved logging in to the newly created server, downloading the puppet agent and config, and installing it, or a script at best. We can do better than that.
The Puppet Master needs to store agent binaries
To make setup of the agent easier we can store binaries of the agent installers for any OS or OS version that we are going to need. This can actually be done in the Puppet Master. We log in to the Puppet Enterprise console, and go to the Classification section. There will be some pre-defined groups done by the Puppet Enterprise installation. Expand “All Nodes”, then expand “PE Infrastructure”. Select the item “PE Master”. Now you are in the group definition, select the “classes” tab, which then should look similar to the following example:
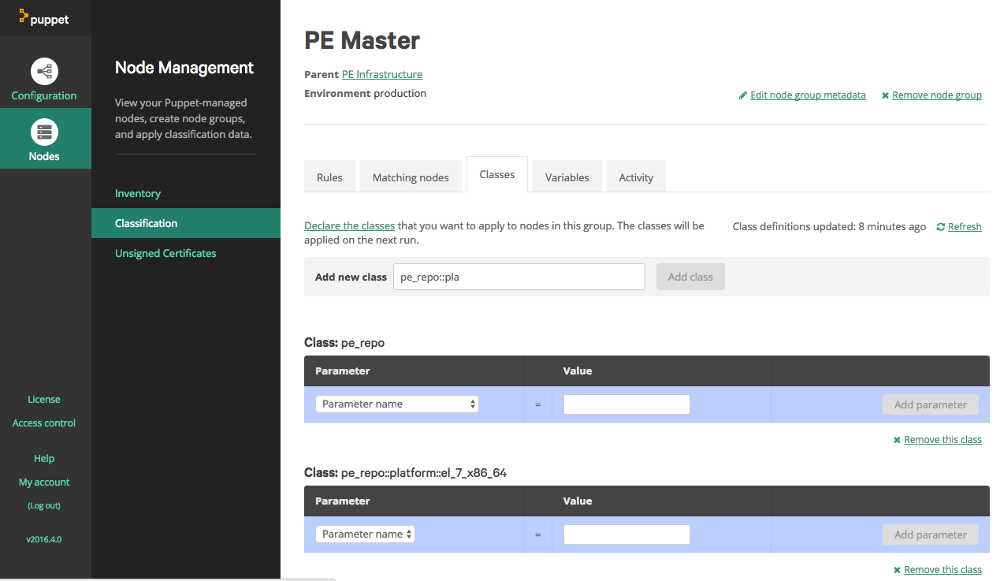
At this point you will see a list of classes already assigned to this group. In the “Add new class” textbox type ‘pe_repo::platform’, this should case an autocomplete popup to appear listing the possible classes:
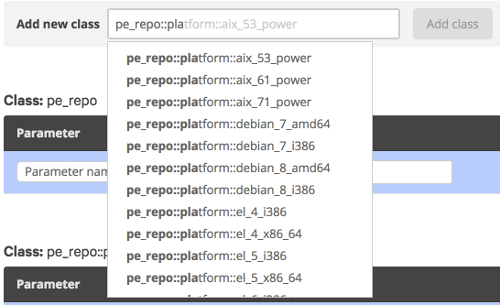
Find the entry for the OS and version you require, select it, and click “Add class”. At this point the Puppet Console will ask you to confirm changes. Once they are confirmed Puppet will run through the required processes, and download the agents, storing them locally.
Node Classification
Now whether we are assigning a role to a server via fact or we are using an External Node Classifier (ENC), a puppet node needs be to classified, so the server can determine what configuration manifests to generate and provide to the puppet agent. ( This step does assume you have configured branches in your control-repo for environments correctly). In this situation we are using Groups in the Puppet Enterprise console. A group has been created for each environment, with subgroups being created for each server role or type. The groups use facts to determine which servers belong in which group.
We login to our Puppet Management Console and go to the Node Management - Classification section. Click “Add Group” and input the required details. To make it easy the Group name and Environment should match the environment name used in the UserData example further on.
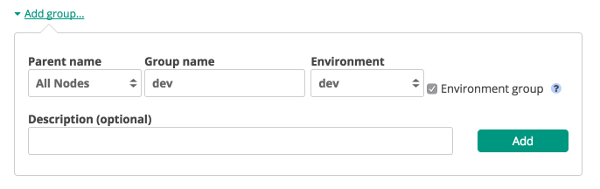
Once the group is created we click on it and start on the rules to classify nodes:
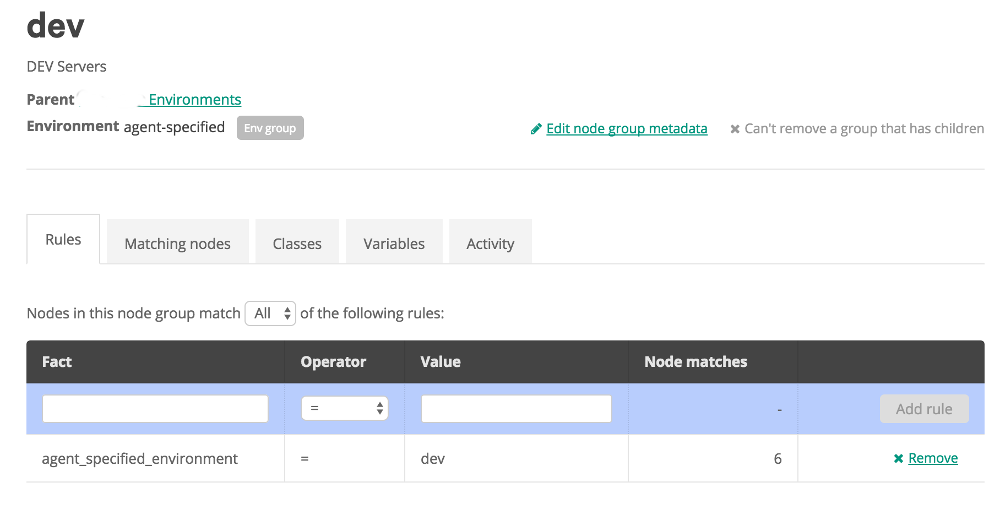
In the rules tab, we start by typing the fact name that we want in the the Textbox below fact. In this case it is “agent_specified_environment” as the agent is going to tell us what it belongs to. Then we select the Operator, with standard options like must equals, does not equal, and some various like options. Then we input the value we want the fact to be (or not be). Then click “Add Rule”. And apply the changes. At this point we can go to the classes tab to add items to this group, or create Subgroups for further detailed classification. The classes to add would be things like roles and profiles, which should be defined to do configuration on the agent for us.
Creating the Agent Node
Now we will move on to the actual creation of an EC2 instance and the configuration of the puppet agent. However you choose to create EC2 instances should work, as long as you have access to provide user_data. That is the key. To clarify, user_data is a set of commands or script that is run when the the instance starts up.
Most of my work is usually done in Ansible, but here I will show you a snippet of cloudformation template user_data:
UserData:
Fn::Base64: !Sub |
#!/bin/bash
echo ${hostname}.localdomain > /etc/hostname
sed -i '/HOSTNAME/c\HOSTNAME=${hostname}.localdomain' /etc/sysconfig/network
echo preserve_hostname=true >> /etc/cloud/cloud.cfg
curl -k https://puppet.localdomain:8140/packages/current/install.bash | sudo bash -s main:certname=${hostname}.localdomain main:server=puppet.localdomain custom_attributes:challengePassword=${puppet_challenge_password}
systemctl stop puppet
echo "environment = ${environment}" >> /etc/puppetlabs/puppet/puppet.conf
echo -e "[agent]\npluginsync = true" >> puppet.conf
mkdir -p /etc/puppetlabs/facter/facts.d
echo "service=${service}" >> /etc/puppetlabs/facter/facts.d/facts.txt
systemctl enable puppet
sudo rebootAnd to explain what is happening here: Lines 4,5 and 6 deal with setting the hostname of the server, and making it stick during start and stop processes. Usually I wouldn’t do this for dynamic EC2 instances, but for this environment it was required.
Line 7 downloads the puppet agent install script from the Puppet Master server and then runs it.
- main:certname defines the name used in the certificate the puppet agent generates. The cert is what the agent and master use to identify it is a valid agent.
- main:server defines the puppet master server fqdn the agent will connect to.
- custom_attributes:challengePassword is a password configured in the master, that the agent will use to authenticate its registration.
Line 8 stops the puppet agent allowing us to do further config.
Line 9 sets the environment the agent will define itself as. This is used to help the Puppet Master classify the agent automatically.
Line 11 and 12, Sets custom facts for puppet to utilise. These facts are loaded by the agent and presented to the Master. They can then be used to further classify the agent, or be used as variables in manifest execution.
The new agent is then rebooted so ensure the new hostname and config are set.
Autosign or Challenge Password?
When we register agents there are a few options we can use. By default Puppet waits for an Admin to login and approve the registration. Thats far too manual however. We can also autosign registrations, so agents get added automatically, but we probably don’t want every agent that gets installed to add itself to the inventory. Every agent uses a puppet node entry from the license, either using them up, or costing more money. There is an option with autosign.conf to only approve agents with certain names in their fqdn. But that could still mean more registrations than we actuall want.
The last option is a challenge password. This blog explains the option quit well: https://danieldreier.github.io/autosign/. The process involes installing the correct gem on the Puppet Master and running through the config. During the process we specify a password. This is logged in the configuration, and then must be used when the Puppet agent creates its cert request (As shown in the userdata example above). The password allows the agent to authenticate with the Master. Allowing us to make our configuration process a little more secure.
Off and Running
Going through all those details above, we can now deploy an EC2 Instance and know that it will be configured without any hands on work. And it will continue to be managed by Puppet. Deployment and Config management handled automatically. That’s the whole premise of DevOps isn’t it. Hope you are all doing well. Hopefully the next blog post will be sooner rather than later.







 These days I am a DevOps Engineer. There’s lots of debate into what DevOps is, but really it’s an
evolution of things that have been done before, what is being done now, and what new technologies
will come out of the industry. It’s the automation of systems building and management, the deployment
of configuration and applications, and the ability to scale all of those systems and processes.
Very much designing things to be as hands off as possible. If you are a systems admin that has
scripted installs of servers or configurations, you have been doing DevOps. If you are a developer
that has automated the testing and deployment of an application, you have been doing DevOps. And
it progresses from there. Really there are many other places that probably define it better than
I can. But it’s where I am now, and I quite enjoy the tech and the logistics behind designing
and implementing things in this space.
These days I am a DevOps Engineer. There’s lots of debate into what DevOps is, but really it’s an
evolution of things that have been done before, what is being done now, and what new technologies
will come out of the industry. It’s the automation of systems building and management, the deployment
of configuration and applications, and the ability to scale all of those systems and processes.
Very much designing things to be as hands off as possible. If you are a systems admin that has
scripted installs of servers or configurations, you have been doing DevOps. If you are a developer
that has automated the testing and deployment of an application, you have been doing DevOps. And
it progresses from there. Really there are many other places that probably define it better than
I can. But it’s where I am now, and I quite enjoy the tech and the logistics behind designing
and implementing things in this space. The whole premise behind this, is designing a way that your systems, infrastructure or applications
can be created as code. That way it can be version controlled for changes, and can be repeated quickly
and reliably. Systems use to be built carefully and have a long-life, requiring long-term maintenance,
which allows the possibility of config drift. That drift often being the bane of a support person.
Now it is all about being able to destroy a problematic server and recreate it’s state quickly
(usually minutes, maybe hours).
The whole premise behind this, is designing a way that your systems, infrastructure or applications
can be created as code. That way it can be version controlled for changes, and can be repeated quickly
and reliably. Systems use to be built carefully and have a long-life, requiring long-term maintenance,
which allows the possibility of config drift. That drift often being the bane of a support person.
Now it is all about being able to destroy a problematic server and recreate it’s state quickly
(usually minutes, maybe hours).